Microsserviço 8

Quando estamos iniciando em microsserviços, temos inicialmente a visão lógica da arquitetura e posteriormente passamos para a visão física. A visão lógica abstrai muito da visão física, ocultando uma série de complexidades que tornam-se evidentes quando são executados em uma infraestrutura real.
Instâncias
O primeiro ponto que devemos observar é ter várias instâncias do microsserviço, já que assim podemos lidar com mais carga de trabalho, além de aumentar a robustez do sistema, pois a falha em uma instância será mais facilmente tolerada. O número de instâncias que serão necessárias dependerá do contexto da aplicação e de outros apectos como a redundância necessária, workload esperado, entre outros; por exemplo, permitir distribuir do microsserviço não só entre várias máquinas, mas também em vários datacenters a fim de mitigar a indisponibilidade de um datacenter inteiro.
Banco de dados
O banco de dados é outro componente importante. O banco de dados usado por um serviço para gerenciar o estado será considerado oculto dentro do microsserviço, por isso não será compartilhado entre microsserviços distintos. Mesmo tendo várias instâncias de um microsserviço acessando o mesmo banco de dados, isso não viola a regra de não compartilhamento porque, nesse contexto, a manipulação dos dados continua com um único microsserviço lógico.
Ainda no contexto de banco de dados, assim como os microsserviços, existe a necessidade de escala a fim de ter a capacidade de trabalhar com um workload maior. Para isso, uma estratégia pode ser dividir a carga de escrita da carga de leitura em nós distintos. Com isso, encaminhar o tráfego para instâncias de leitura permitirá que a instância de escrita tenha mais capacidade disponível.
Existem situações em que podemos ter a mesma infraestrutura física suportando vários banco de dados isolados do ponto de vista lógico. Isso permite que o mesmo hardware sirva vários microsserviços, reduzindo custos de licença e de gerenciamento do próprio banco de dados. Mesmo os banco de dados executando na mesma engine e no mesmo hardware, temos o isolamento entre eles do ponto de vista lógico. Claro que, caso a infraestrutura compartilhada pelos banco de dados falhe, teremos um cenário de indisponibilidade total.
Essa abordagem acaba sendo muito utilizada por empresas que administram e executam o banco de dados on-premises, diferente daquelas que utilizam núvem pública que, normalmente, acabam provisionando uma infraestrutura de banco de dados para cada serviço. O custo é maior, entretanto o controle e isolamento também são maiores.
Ambiente e Implantação
Finalizado o desenvolvimento, chegou o momento do microsserviço ser implantado no ambiente. Não existe um número fixo de ambientes que devem existir, já que isso pode variar muito dependendo do tipo de software e como será entregue ao usuário final. Além disso, dependendo do ambiente de implantação, o modo de implantação também pode variar, por exemplo, em UAT podemos ter o microsserviço rodando com 2 instâncias mas no mesmo datacenter, já em produção, temos o microsserviço executando 2 instâncias em 2 datacenters diferentes. Ou seja, a topologia do microsserviço muda de um ambiente para outro.
O ponto é que, dependendo do ambiente que o microsserviço foi implantado, pode ser que nem todos os serviços de apoio estejam disponíveis. Para esses casos, podem ser substituídos por mocks para testes. O cenário ideal é que os ambientes sejam cópias exatas do ambiente de produção, todavia acaba sendo inviável pelo alto custo que poderia gerar.
Sendo o ambiente uma cópia ou mocks para testes, o ideial é ter um feedback o mais rápido possível se o microsserviço funciona ou não, já que o quanto antes soubermos de um problema, mais rápido será para corrigi-lo e menor será o impacto da falha.
Existem diversas abordagens de como implantar um microsserviço, mas alguns princípios precisam ser utilizados:
- execução isolada: instâncias de microsserviços têm seus próprios recursos computacionais, e sua execução não causa impacto nas instâncias de outros microsserviços executando nas proximidades;
- foco na automação: uso de tecnologias que facilite a automação já que será extremamente necessário à medida que o número de microsserviços aumentarem;
- infraestrutura como código: represente a infraestrutura como código para facilitar a automação;
- implantação sem downtime: a implantação de uma nova versão do microsserviço deve ser feita sem nenhum downtime para os usuários;
- gerenciamento de estado desejado: mantenha os microsserviços no estado desejado, iniciando novas instâncias caso necessário;
Execução isolada
Executar várias instâncias de microsserviços na mesma máquina física ou virtual acaba prejudicando o princípio de implantação independente, pois sem isso, podemos ter diversos microsserviços se digladiando por recuros computacionais. Assim, a execução do microsserviço com o uso dos containers acada sendo a solução ideial.
Foco na automação
A migração para microsserviços gera mais complexidade para a área operacional. À medida que o número de microsserviços aumenta, a automação será cada vez mais importante. Além disso, a automação permite que os desenvolvedores provisionem serviços de forma mais facilitada.
Infraestrutura como código
IaC é um conceito em que a infraestrutura é configurada como código. A ideia é definir de forma textual como que um determinado item de infraestrutura deve ser provisionado, definindo tamanho, configurações, etc. Além disso, com o versionamento dessa infraestrutura, temos mais transparência sobre quem alterou o quê.
Implantação sem downtime
O ponto é que queremos fazer mudanças e implantá-las sem impactar o consumidor upstream. Sem uma implantação sem downtime, teríamos de coordenar a implantação com todos os consumidores upstream já que teríamos uma interrupção no serviço.
Com a implantação sem downtime, podemos fazer entregas mais frequentes e os consumidores upstream nem perceberão que uma nova versão foi lançada. Vale a pena pensar sempre em uma arquitetura com esse princípio em mente desde a concepção.
Gerenciamento de estado desejado
A ideia é ter a capacidade de especificar os requisitos de uma infraestrutura para sua aplicação e fazer com que esses requisitos sejam mantidos sem intervenção manual. Caso o estado desejado deixou de existir, a plataforma subjacente deve atuar para trazer a aplicação para o estado desejado novamente.
Por exemplo, queremos que sempre existam 3 instâncias da aplicação em execução. Caso aconteça algo que mude esse estado desejado de 3 instâncias, cabe à plataforma atuar e reestabeler o estado desejado. O kubernetes é uma ferramenta desse tipo. Também existe o auto scalling group de núvens públicas.
Opções de implantação
Queremos executar os microsserviços de forma isolada, sem downtime, tendo uma infraestrutura como código e gerencimanto de estado contínuo. Para atender a esses pontos, definir a opção de implantação será um determinante. Podemos implantar em:
- máquina física: microsserviço executa diretamente em uma máquina física, sem virtualização;
- máquina virtual: micosserviço executa em uma máquina virtual;
- container: microsserviço executa em um container separado, podendo estar em uma máquina física ou virtual;
- container de aplicações: microsserviço executa em um container de aplicações que gerencia outras instâncias de aplicações;
- PaaS: microsserviço executa em uma plataforma como serviço com um nível mais alto de abstração;
- FaaS: microsserviço executa como uma função e é gerenciado por uma plataforma subjacente;
Máquinas físicas
Uma opção cada vez mais rara, não havendo nenhuma camada de virtualização ou conteinerização entre o microsserviço e o hardware. Essa abordagem faz com que tenhamos subutilização do equipamento, em que recursos restantes ou sobressalentes não desperdiçados.
Por isso, para solucionar esse problema, surgiu a virtualização, permitindo a coexistência de várias máquinas virtuais na mesma máquina física. Com isso temos uma maior e melhor utilização da infraestrutura.
Máquinas virtuais
Podemos ter um uso mais racional do hardwre subjacente dividindo a máquina física já existente em diversas máquinas virtuais menores. Além disso, podemos atribuir partes do hardwre físico - CPU, memória, disco - para cada uma das máquinas virtuais, tendo assim ambientes de execução isolados.
Cada VM contém um S.O completo e um grau de isolamento entre as instâncias.
Um ponto a ser observado é que à medida que adicionamos mais VMs, haverá cada vez menos recursos a serem distribuídos entre as VMs. Isso acontece porque os recursos do hardware físico também serão utilizado pelo hipervisor, cuja função é mapear os recursos do host virtual para o host físico, e atuar como uma camada de controle. Para isso, o hipervisor precisa reservar recursos para fazer seu trabalho. Quanto mais hosts o hipervisor gerencia, mais recursos serão necessários.
Pode ser uma opção de uso caso níveis mais rigorosos de isolamento são necessários ou não for possivel conteinerizar o microsserviço.
Container
Para muitos, um padrão consolidado no mercado e a escolha preferida para execução de arquiteturas de microsserviços. Diferente das VMs, com o uso de containers, não temos o hipervisor. O container faz uso do kernel da máquina subjacente, e é nesse kernel que está a árvore de processos de cada container.
Tendo em vista a leveza do containers, podemos ter muito mais deles executando no mesmo hardware, em comparação com o que seria possível com as VMs, já que agora não temos recursos sendo compartilhados com o hipervisor.
O containers podem ser vistos como uma ótima maneira de executar softwares confiáveis.
O Docker foi o grande divisor de águas, deixando o uso de container muito mais viável. Atividades como provisionamento dos containers, problemas de rede, armazenamento de imagens em registry, foi facilitado pelo Docker. Além disso, independente a linguagem usada para desenvolver um serviço, conseguimos tratar todos do mesmo modo já que, no final, tudo será uma imagem de container.
Entretanto, gerenciamento de estado precisa ser tratado por outra ferramenta, por exemplo, o Kubernetes, que resumidamente, é uma forma de gerenciar containers distribuídos em várias máquinas.
Container de aplicações
A ideia são aplicações ou serviços distintos em um único container de aplicações. Exemplos são o .NET com IIS, Java com Wildfly (JBoss) ou Tomcat.
Usando essa abordagem, temos tempos de inicialização e ciclos de feedback mais lentos, fazer gerenciamento apropriado do ciclo de vida das aplicações pode ser mais problemático e mais complexo, além de ser mais complicado analisar e gerenciar o uso de recursos e threads, pois teremos muitas aplicações compartilhando o mesmo processo.
Pela falta de isolamento desse modelo, está sendo cada vez mais raro a adoção dessa abordagem.
PaaS
Com um alto nível de abstração, apenas geramos um artefato e disponibilizamos. A plataforma provisiona e executa esse artefato automaticamente. Não temos a preocupação de gerenciamento da plataforma subjacente. Um ponto de observação é que se o microsserviço for muito diferente do padrão esperado pela plataforma, pode acabar não sendo uma opção para adoção.
FaaS
Termo popularizado com o serverless. Detalhes de gerenciamento e configuração ficam ocultos, o foco maior estará no negócio e features, não em infraestutura, diminuindo o overhead operacional com o qual se preocupar.
Com a característica de ser stataless, o código implantado é tratado como uma "função", sendo executado somente quando houver um evento. A plataforma subjacente cuida da inicialização e encerramento dessas funções, além de lidar com execuções concorrentes, de modo que seja possível ter várias cópias executando ao mesmo tempo quando necessário.
Entretanto, essa abordagem não permite um controle sobre os recursos atribuídos a cada chamada da função. Algumas plataformas permitem controlar somente a memória concedida a cada função, mas o controle direto de CPU e I/O não é permitido. Dessa forma, podemos acabar tendo que conceder mais memória para uma função, mesmo que não precise, somente para ela tenha a CPU necessária.
Outro ponto é o tempo de execução da função já que, dependendo da plataforma, pode haver diferença.
O uso de FaaS pode não fazer sentido quando existe a necessidade de realizar ajustes finos relacionados aos recursos disponíveis às funções.
Um desafio que existe é o chamado cold start, que é o tempo que a função leva para inicializar. Runtimes como a JVM e .NET podem sofrer significativamente com esse problema, já linguagens cujos runtimes tenham inicialização rápida (Go, Python, Node.js) podem anular o efeito desse problema com eficácia.
No mapeamento de funções como microsserviços, podemos ter a seguintes abordagens:
- função por microsserviço: uma instância de microsserviço se torna uma função, com todos dos serviços disponíveis. O conceito de uma unidade de implantação é mantido.
- função por agregado: agregados são um conjunto de objetos que são gerenciados como uma única entidade. Assim, teríamos uma função para cada agregado, já que podemos garantir que toda a lógica para um único agregado esteja autocontida na função, facilitando a implementação e o gerenciamento do ciclo de vida do agregado. Teremos várias unidades de implantação indepentendes, mas com o conceito lógico que todas compõem um único microsserviço. Não seria um problema se todas as funções compartilhassem o mesmo banco de dados, se considerarmos que a mesma equipe mantém todas as funções e conceitualmente continuamos tendo um único serviço, mas composto de várias funções.
Se o uso de FaaS for uma opção, vale a pena explorar considerando as facilitadade e o menor gerenciamento de infraestrutura para execução do workload. Agora, caso a conteinerização é o caminho, em grande escala, o Kubernetes acabará sendo a direção a ser seguida.
Kubernetes
Tratando de implantação, o kubernetes pode ser definido como uma plataforma de orquestração de containers, lidando com o modo e o lugar em que as cargas de trabalho em container são executadas. Apenas dizemos o que queremos e como queremos. O Kubernetes descobre como escalonar o workload e lidar com o estado desejado definido previamente.
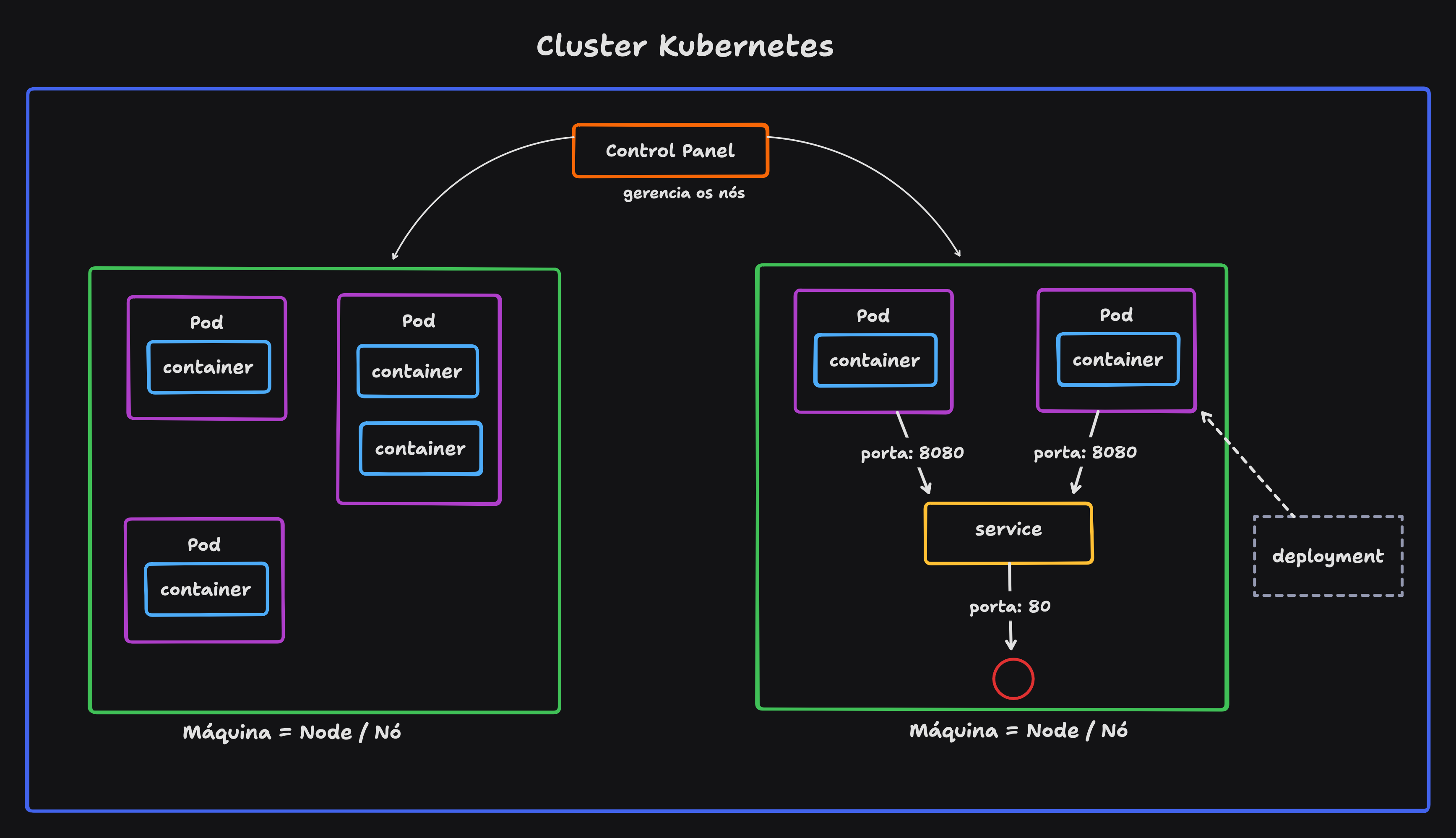
No cluster Kubernetes, temos:
- node: máquinas que compõem o cluster;
- control panel: softwares que gerenciam os nós;
- pod: composto de 1 ou N containers implantados juntos. O padrão é ser um container por pod;
- service: endpoint estável para roteamento, fazendo o mapeamento dos pods em execução para uma interface de rede disponível no cluster. Um pod é efêmero, mas o serviço se mantém em execução. Pods são mapeados para serviço.
- deployment: modo de aplicar mudanças nos pods. Podemos fazer rolling upgrades, rollbacks, aumentar nós, etc.
O conceito de plafaforma do kubernetes estar mais relacionada à possíbilidade de customização, montar a própria plataforma com a instalação de softwares auxiliares usando, por exemplo, o gerenciador de pacotes helm. Podemos escolher a ferramenta que quisermos para tarefas específicas. No entando, também pode levar à tirania da escolha - ficando sobrecarregados com tantas opções. Plafaformas como o Openshift eliminam a necesidade de fazermos escolhas, já que algumas decisões já foram tomadas por nós.
Assim, apesar do kubernetes fornecer uma camada de abstração portável para execução de containers, na prática, não é tão simples quanto tomar uma aplicação que funciona em um cluster e esperar que ela vá funcionar em outro lugar. Aplicações criadas com base no kubernetes são portáveis entre clusters kubernetes na teoria, mas em sempre é o que acontece na prática.
A alta customização do kubernetes dificulta a portabilidade das aplicações entre clusters.
Usar o kubernetes exige alguns pontos de atenção. Gerenciar um cluster kubernetes não é uma ativadade simples e a experiência que dos desenvolvedores terão em usar a instalação do kubernetes dependerá da eficiência da equipe que vai administrar o cluster. Pode valer a pena o uso de um cluster gerenciado. Entretando, tendo poucos desenvolvedores e alguns microsserviços, é provável que o kubernetes seja um exagero, mesmo com o uso de uma plafaforma gerenciada.
Entrega progressiva
Definido o ambiente e a implantação, é hora de entregar a solução. Ao passar dos anos, estamos implantando softwares para os nossos usuários de modo mais inteligente e com muito menos riscos, resultado de novas técnicas que surgiram nos últimos anos.
Há uma série de atividades que executamos antes de disponibilizar o software aos usuários finais, as quais nos ajudam a identificar problemas antes de impactá-los. Os testes em pré-produção desempenham um papel crucial nesse cenário.
Técnicas como blue-green deployment, feature flags, canary releases, parallel runs são algumas abordagens que podemos utilizar para fazer o que chamamos de entrega progressiva. Basicamente, a ideia é separar o conceito de implantação do conceito de entrega.
A implantação é a entrega, deploy do software no ambiente. Já o lançamento, é fazer com que o sistema ou parte dele se torne disponível aos usuários. Os rollouts, que agora pode ser divididos em fases, poderão ser controlados pelo dono do produto.
No blue-green deployment, temos a versão atual ativa (blue) e, em seguida, implantamos a nova versão ao lado da versão antiga (green). Verificamos se a nova versão está funcionando conforme esperado e, caso esteja, redirecionamos os clientes para que vejam a nova versão do software. Caso algum problema seja identificado antes da virada, nenhum cliente será impactado.
No feature flags, as funcionalidades são ocultadas a partir de flags (toggle) que podem ser utilizadas para ativar ou desativar. Essa abordagem permite implantar funcionalidades mesmo que não estejam concluídas, já que estarão ocultas aos usuários. Logo, podemos ativar uma feature em um horário específico ou desativar caso algum problema esteja ocorrendo.
Com canary releases, a ideia é que um subconjunto de usuários terão acesso à funcionalidade. Caso haja algum problema com o rollout, apenas parte dos usuários serão impactados. Caso a funcionalidade esteja funcionando como esperado para o grupo canário, o rollout poderá ser expandido para todos os usuários.
Com parallel runs, executamos duas implementações diferentes da mesma funcionalidade, lado a lado, enviando a mesma requisição para das duas implementações, em microsserviços seriam 2 serviços distintos, e comparamos os resultados para ver se estão como esperado. Todavia, apenas uma requisição será a fonte da verdade.